Các nhà khoa học nay đã tìm ra một công cụ mới, tận dụng sức mạnh của trí tuệ nhân tạo (AI) để tự tạo ra các video có hình ảnh một người phát biểu với nguồn gốc âm thanh bài diễn văn được chọn tùy ý, thậm chí không phải của người trong video đang nói. Cụ thể, đây là cơ chế mô phỏng tái tạo các chuỗi hình ảnh nhân tạo, và ở đây đối tượng được thử nghiệm là chính là… Tổng thống Obama cùng bài diễn văn của mình.
Đây không phải là phần mềm được làm ra với chủ đích cố tình tạo dựng nên những luồng thông tin giả mạo. Thực chất nó là một phần nhỏ trong một chương trình lớn hơn nhằm phát hiện ra những video giả mạo. Các chuyên gia chỉ trích một phần chức năng để minh họa mà thôi.
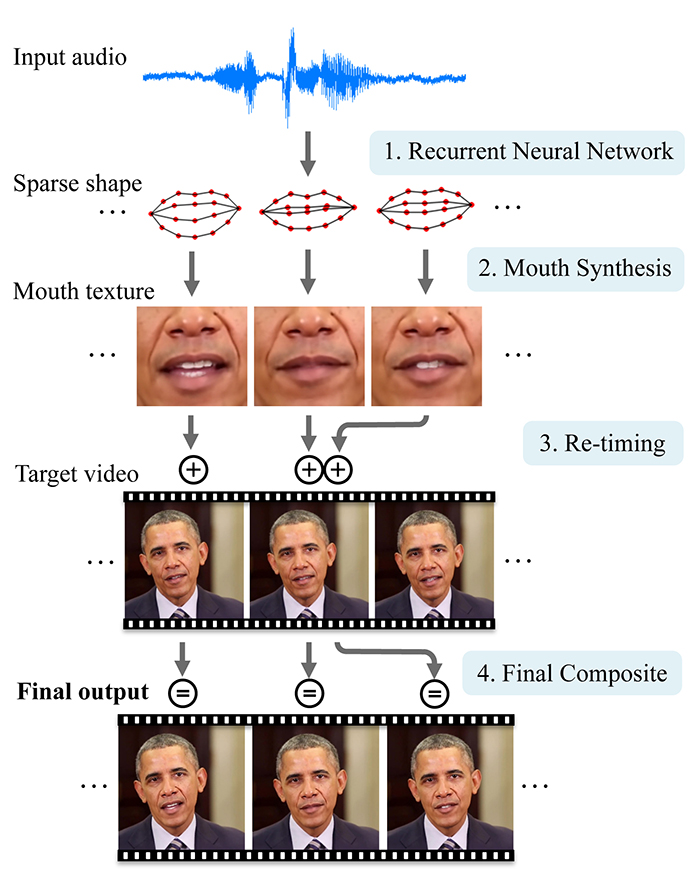
Cách thức hoạt động chi tiết của AI này.
Cơ chế hoạt động của nền tảng này là ở chỗ AI sẽ khai thác và phân tích nguồn dữ liệu âm thanh, sau đó tạo nên những khuôn mẫu hình ảnh cho miệng của nhân vật chủ thể trong video sao cho khớp với từ ngữ đang nói ra.
“Loại hình này chưa từng xuất hiện trước đây. Cách thức chuyển đổi từ âm thanh sang video mô phỏng này sẽ có thể được dùng để ứng dụng vào một số mục đích cho các buổi họp lớn, hay tiến xa hơn là công nghệ hình chiếu thực tế ảo,” Ira Kemelmacher-Shlizerman, một trong những chuyên gia liên quan cho biết.
Demo công nghệ chuyển đổi mô phỏng tái tạo âm thanh sang hình ảnh.
Kết quả thu được thực sự thuyết phục, bạn có thể chứng kiến từ video trên. Mỗi quá trình chuyển đổi sẽ cần cả âm thanh và video gốc để phân tích mẫu dữ liệu, nhưng nếu âm điệu phát ra từ miệng được tạo ra từ luồng khí mỏng nhẹ, nó sẽ khó mà tái tạo chính xác diễn biến đó 100%. Khi xét đến mục đích phát hiện video giả, thuật toán trên sẽ được tinh chỉnh và đảo ngược.